-
파이썬으로 시작하는 데이터 사이언스 - 2. 공공데이터 로드 및 데이터 미리보기공부일기/부스트코스 2020. 11. 19. 19:18
공공데이터 포털에서 '상가(상권)정보_의료기관' 데이터를 갖고 학습을 진행하며 Jupyter notebook을 사용한다.
1. 필요한 라이브 불러오기
import pandas as pd import numpy as np # 수치 계산을 위한 라이브러리 import seaborn as sns # 시각화를 위한 라이브러리2. 시각화를 위한 폰트 설정
import matplotlib.pyplot as plt # 데이터 시각화 라이브러리 plt.rc('font', family='Malgun Gothic') # WINDOWS 폰트 지정 MAC일 경우 AppleGothic plt.rc('axes', unicode_minus=False) # minus 기호 깨짐 방지 from IPython.display import set_matplotlib_formats # 폰트 선명하게 보이게 하기 set_matplotlib_formats('retina')3. 데이터 로드하기
- 판다스에서 데이터를 로드할 때 .read_csv를 사용한다.
- 데이터를 로드해서 df 라는 변수에 담는다.
- .shape를 통해 데이터의 개수를 알 수 있다. 결과는 (행, 열) 순으로 출력된다.
df = pd.read_csv("data/소상공인.....csv", low_memory=False) # 그냥 실행하면 경고가 뜬다. 하라는 대로 low_memory=False를 지정해준다. df.shape>>> (91335, 39)
91335 줄, 39 열을 가진 표로 구성된 데이터라고 보면 된다.
4. 데이터 미리보기
head()와 tail()을 통해 데이터를 미리 볼 수 있다.
이 부분은 앞에서 다루었으므로 pass..
sample()을 사용하면 랜덤으로 한 index를 보여준다. 기본 값은 1 ()안에 숫자를 넣으면 해당 수 만큼의 데이터를 출력.
5. 데이터 요약하기
- 5.1 요약정보
.info()
df.info() # info로 데이터의 요약을 본다.
실행 결과. 사용된 자료형과 데이터 용량도 알 수 있다. - 5.2 컬럼명 보기
.columns
df.columns
실행 결과 - 5.3 데이터 타입
.dtypes
df.dtypes.head() # head()를 사용해 상위 5개 값만 확인했다.
6. 결측치
.isnull()
df.isnull().head() # isnull을 활용해 값이 없는 부분이 있는지 확인한다. True일 경우 값이 없음.
True는 값이 없음. False는 값이 있음. null_count = df.isnull().sum() null_count # True == 1 이기 때문에 .sum()을 사용하게 되면 해당 숫자만큼 값이 없다는 것을 나타낸다.
.isnull()로 True False를 구별하고 .sum()을 사용하게 되면 각 컬럼에 True와 False를 계산한 값이 나오게 된다.
True == 1, False == 0 이므로 출력된 숫자는 해당 컬럼에서 비어있는 값이 없는 index의 개수라고 생각하면 될 것 같다.
위의 형식은 한번에 보기 어려우므로 막대그래프로 표현할 수 있다.
.plot.bar()
# .plot.bar 를 이용해 막대그래프로 표현한다. null_count.plot.bar(figsize = (5,7))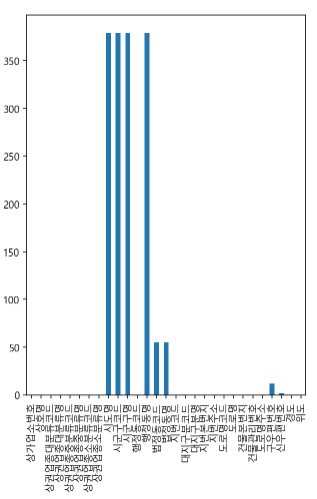
글씨가 누워져 있어 보기가 힘들다. .plot.bar를 이용해 그래프를 출력했으나 x축의 글자들이 누워있어 보기가 힘들다. .plot.bar(rot=30) 이런식으로 글자의 각도를 조절할 수 있으나 보다 확실한 방법은 아래와 같다.
null_count.plot.barh(figsize = (5,7))
.plot.barh를 사용했다. .barh는 x축과 y축을 바꿔서 보여준다.
figsize는 그래프의 크기를 설정할 수 있게 한다. (가로, 세로)를 의미한다.
.reset_index()
df_null_count = null_count.reset_index() df_null_count.head(10)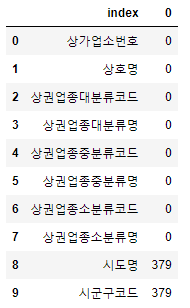
rest_index()를 실행하게 되면 데이터프레임의 형태로 값을 보여준다.
해당 값을 df_null_count로 다시 받아, 상위 10개의 데이터만 추출했다.
7. 컬럼명 변경하기
df_null_count.colums = ["컬럼명","결측치수"] df_null_count.head()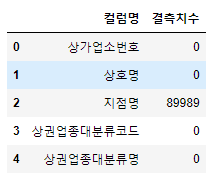
위 사진의 컬럼명 index, 0이 컬럼명, 결측치수로 변경됐다.
8. 정렬하기
.sort_values( by= )
( ) 안의 'by='는 생략할 수 있으나 어떤 컬럼을 기준으로 할 것인지를 나타내는 매개변수 한가지는 반드시 들어와야 한다.
df_null_count_top = df_null_count.sort_values("결측치수", ascending=False).head(10) df_null_count_top데이터를 "결측치수"의 값을 기준으로 정렬한다. ascending=False 이므로 내림차순으로 정렬.

9. 특정 컬럼만 불러오기
df["지점명"]

지점명 컬럼을 불러왔고, 결측치가 많다는 것을 확인할 수 있다.
NaN : Not a Number의 약자. 결측치를 의미한다.
.tolist()
drop_columns = df_null_count_top["컬럼명"].tolist() drop_columns"컬럼명"의 컬럼만 가져와 list형식으로 만들고, drop_columns라는 변수로 지정한다.
tolist의 기능은 값들을 리스트 형식으로 만들어준다는 것이다. 출력해보면 아래와 같다.

10. 제거하기
print(df.shape) df = df.drop(drop_columns, axis = 1) print(df.shape)
drop_columns에 지정한 컬럼들을 버리기 전 shape과
버리고 난 후의 shape의 차이.
10개의 컬럼이 없어졌다.
df.info()
결측치들을 찾아내고, 결측치가 많은 컬럼들을 순서대로 모아서 10개의 컬럼들을 제거했다.
처음 데이터와 비교했을 때 7MB 정도의 용량 차이가 난다.
결측치가 있게 되면 값을 비교하고, 어떤 가설을 세우고, 그 결과를 뽑아내기가 어렵기 떄문에 제거하는 게 아닐까 싶다.
'공부일기 > 부스트코스' 카테고리의 다른 글
파이썬으로 시작하는 데이터 사이언스 - 4. 데이터 전처리 (0) 2020.11.24 파이썬으로 시작하는 데이터 사이언스 - 3. 데이터 요약 및 추출 (0) 2020.11.20 파이썬으로 시작하는 데이터 사이언스 - 1. Pandas (0) 2020.11.18 자바스크립트의 시작 - 3. Javascript 활용 (0) 2020.10.01 자바스크립트의 시작 - 2. Javascript 제어문, 함수, 객체 (0) 2020.09.29