-
Java 항해일지 10. 멀티스레드 프로그래밍공부일기/자바 스터디 2021. 1. 24. 19:32
목표
자바의 멀티스레드 프로그래밍에 대해 학습하세요.
학습할 것 (필수)
- Thread 클래스와 Runnable 인터페이스
- 스레드의 상태
- 스레드의 우선순위
- Main 스레드
- 동기화
- 데드락
프로세스와 스레드
프로세스의 사전적 정의는 일의 과정이나 공정이며, 위키백과를 통해 얻은 의미는 다음과 같다.
그렇다면 스레드란 무엇일까. 마찬가지로 위키백과를 통해 얻은 의미는 아래와 같다.
간단히 말해 프로세스는 연속적으로 실행되고 있는 컴퓨터 프로그램, 스레드는 프로그램 내에서 실행되는 흐름의 단위이다.
비유를 통해 쉽게 설명하자면 이렇게 말할 수 있을 것이다. 컴퓨터 하나의 주방이라고 친다면 이 주방에서 여러 가지 메뉴(프로그램)들이 만들어지고 있을 것이다. 예를 들어 파스타가 만들어진다고 치자. 파스타 주문이 들어와 파스타를 만드는 과정 자체는 프로세스다. 이 주방에서 파스타뿐만 아니라 리조또, 스테이크 등을 조리할 수 있다면 각각 다른 프로세스를 실행할 수 있는 것이고, 여러 개의 프로세서가 사용되고 있으므로 멀티프로세싱이라 한다. 또 각각의 모든 메뉴들이 동시간에 조리되고 있다면 멀티태스킹이 되고 있는 것이다.
다시 파스타를 만드는 프로세스로 돌아와서 요리사는 파스타를 만들 때 물을 끓여 파스타면을 먼저 삶을 건지, 소스를 먼저 만들어 놓을 건지를 결정할 수 있다. 이때 하나의 파스타를 만드는 과정(프로세스) 내에서 요리사가 어떤 방식으로 파스타를 완성할 것인지가 스레드이다. 요리사의 실력에 따라 면을 끓이고, 소스를 만들어 그릇에 담는 순서대로 하나씩 실행할 수도 있고, 면을 삶으며 소스를 만들고 그릇에 담는 등 동시에 만들 수도 있을 것이다. 둘 이상의 스레드를 실행하는 경우(면을 삶으면서 소스를 만듦)를 멀티 스레드라 할 수 있다.
Thread 클래스와 Runnable 인터페이스
자바에서 스레드를 구현하는 방법은 크게 두 가지가 있다.
1. thread 클래스를 사용한다.
package javastudy; public class MultiProcessing extends Thread{ public void run() { // 작업내용. Thread 클래스의 run()을 오버라이딩 } }2. Runnable 인터페이스를 사용한다.
package javastudy; public class MultiProcessing implements Runnable { public void run() { // 작업내용. Runnable 인터페이스의 run()을 구현 } }Thread 클래스도 Runnable 인터페이스를 구현한 클래스이므로 결국 어떤 것을 적용하느냐의 차이로 선택할 수 있다. 다만 Thread를 상속받으면, 다른 클래스를 상속받을 수 없기 때문에 인터페이스를 구현하는 방법이 일반적이다.
아래는 스레드의 구현과 실행에 대한 예제이다.
package javastudy; public class MultiProcessing { public static void main(String[] args) { MyThread1 t1 = new MyThread1(); Runnable r = new MyThread2(); Thread t2 = new Thread(r); t1.start(); t2.start(); } } class MyThread1 extends Thread { public void run() { for (int i = 0; i < 10; i++) { System.out.println(getName()); // 조상인 Thread의 getName()을 호출 } } } class MyThread2 implements Runnable { public void run() { for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName()); // 현재실행중인 Thread를 반환 } } }
실행 결과 스레드의 실행
스레드를 생성했다고 자동으로 실행되는 것은 아니며, start()를 호출해야만 스레드가 실행되는데 바로 실행되는 것이 아니라 실행 대기상태에서 자신의 차례가 되어야 실행된다. 이 순서는 OS의 스케쥴러가 작성한 스케쥴에 의해 결정된다.
그리고 한 번 실행이 종료된 스레드는 다시 실행할 수 없다. 하나의 스레드는 start()가 한 번만 호출될 수 있다는 것이다.
만약 위의 예제에서 t1을 한 번더 실행하게 되면 아래와 같이 IllegalThreadStateException이 발생한다.
public class MultiProcessing { public static void main(String[] args) { MyThread1 t1 = new MyThread1(); Runnable r = new MyThread2(); Thread t2 = new Thread(r); t1.start(); t2.start(); t1.start(); } }
이를 해결하기 위해선 새로운 스레드를 생성한 후 start()를 호출해야 한다.
public class MultiProcessing { public static void main(String[] args) { MyThread1 t1 = new MyThread1(); Runnable r = new MyThread2(); Thread t2 = new Thread(r); t1.start(); t2.start(); t1 = new MyThread1(); t1.start(); } }
스레드를 실행시킬 때 run()이 아닌 start()를 호출한다는 것에 의문을 가져보자. start()와 run()의 차이는 무엇일까.
run()
main 메서드에서 run()을 호출하는 것은 생성된 스레드를 실행시키는 것이 아니라 단순히 클래스에 선언된 메서드를 호출하는 것이다.
start()
새로운 스레드가 작업을 실행하는데 필요한 호출스택(call stack)을 생성한 후 run()을 호출해, 생성된 호출스택에 run()을 첫 번째로 올린다.
모든 스레드는 독립적인 작업을 수행하기 위해 자신만의 호출스택을 필요로 하기 때문에, 새로운 스레드를 생성하고 실행시킬 때마다 새로운 호출스택이 생성되고, 스레드가 종료되면 작업에 사용된 호출스택은 소멸된다. 그래서 하나의 스레드에 대해 start()를 두번 이상 호출하면 예외가 발생하게 되는 것이다.

이미지 출처: https://wisdom-and-record.tistory.com/48 스레드의 상태
스레드는 생성된 후 부터 종료될 때까지 아래와 같은 여러 상태를 가질 수 있다.
상태 설명 NEW 스레드가 생성되고 아직 start()가 호출되지 않은 상태 RUNNABLE 실행 중 또는 실행 가능한 상태 BLOCKED 동기화블럭에 의해 일시정지된 상태(lock이 풀릴 때까지 기다리는 상태) WAITING, TIMED_WATING 스레드의 작업이 종료되진 않았지만 실행가능하지 않은 일시정지 상태. TIMED_WATING은 일시정지시간이 지정된 경우 TERMINATED 스레드의 작업이 종료된 상태 스레드의 생성부터 소멸까지의 모든 과정에 대한 그림이다.

(출처 : 자바의 정석 3판 p.527) 쓰레드의 상태와 메소드들의 관계 - 스레드를 생성하고 start()를 호출하면 바로 실행하는 것이 아니라 실행대기열에 저장되어 자신의 차례가 될 때까지 기다린다. 실행대기열은 큐와 같은 구조로 먼저 실행대기열에 들어온 스레드가 먼저 실행된다.
- 실행대기상태에 잇다가 자신의 차례가 되면 실행상태가 된다.
- 주어진 실행시간이 다되거나 yield()를 만녀만 다시 실행대기상태가 되고 다음 차례의 스레드가 실행상태가 된다.
- 실행 중에 suspend(), sleep(), wait(), join(), I/O block에 의해 일시정지상태가 될 수 있다. I/O block은 입출력 작업에서 발생하는 지연상태이다. 사용자의 입력을 기다리는 경우 일시정지 상태에 있다가 사용자가 입력을 마치면 다시 실행대기 상태가 된다.
- 지정된 일시정지 시간이 다되거나, notify(), resume(), interrupt()가 호출되면 일시정지 상태를 벗어나 다시 실행대기열에 저장되어 자신의 차례를 기다리게 된다.
- 실행을 모두 마치거나 stop()이 호출되면 스레드는 소멸된다.
스레드의 실행제어
효율적인 멀티스레드 프로그램을 만들기 위해서는 보다 정교한 스케줄링을 통해 프로세스에게 주어진 자원과 시간을 낭비 없이 잘 사용하도록 프로그래밍 해야 한다. 스레드의 스케줄링을 잘하기 위해 스케줄링과 관련된 메서드를 알아보자
메서드 설명 static void sleep(long millis)
static void sleep(long millis, int nanos)지정된 시간(밀리세컨드, or 나노세컨드)동안 쓰레드를 일시정지시키다. 지정한 시간이 지나고 나면, 자동적으로 다시 실행대기 상태가 된다. void join()
void join(long millis)
void join(long millis, int nanos)지정된 시간동안 쓰레드가 실행되도록 한다. join()을 호출한 쓰레드는 그동안 일시정지 상태가 된다. 지정된 시간이 지나거나 작업이 종료되면 join()을 호출한 쓰레드로 다시 돌아와 실행을 계속한다. void interrupt() sleep()이나 join()에 의해 일시정지 상태인 쓰레드를 깨워서 실행대기 상태로 만든다. 해당 쓰레드에서는 InterruptedException이 발생함으로써 일시정지 상태를 벗어나게 된다. void stop()쓰레드를 즉시 종료시킨다.void suspend()쓰레드를 일시정지시킨다. resume()을 호출하면 다시 실행대기 상태가 된다.void resume()suspend()에 의해 일시정지 상태에 있는 쓰레드를 실행대기 상태로 만든다.static void yield() 실행 중에 자신에게 주어진 실행시간을 다른 쓰레드에게 양보하고 자신은 실행대기 상태가 된다. suspend(), resum(), stop()은 스레드의 실행을 제어하는 가장 손쉬운 방법이지만 suspend()와 stop()이 교착상태(deadlock)를 일으키기 쉽게 작성되어 있어 사용이 권장되지 않는다. 해당 메서드들은 모두 'deprecated'되었으며 하위 호환성을 위해 삭제하지 않았을 뿐 사용해서는 안되는 메서드들이다.
join()과 sleep(), interrupt()에 대한 예시는 이전에 작성한 글을 통해 확인해 볼 수 있다. (young-bin.tistory.com/65)
yield()
yield()는 스레드 자신에게 주어진 실행시간을 다음 차례의 스레드에게 양보한다.
예를 들어 스케줄러에 의해 1초의 실행시간을 할당받은 스레드가 0.5초의 시간동안 작업한 상태에서 yield()가 호출되면, 나머지 0.5초의 작업시간은 포기하고 다시 실행대기상태가 된다. yield()와 interrupt()를 적절히 사용하면, 프로그램의 응답성을 높이고 보다 효율적인 실행이 가능하게 할 수 있다.
쓰레드의 우선순위
스레드는 우선순위라는 속성(멤버변수)을 가지고 있는데 이 우선순위 값에 따라 스레드가 얻는 실행시간이 달라진다. 스레드가 수행하는 작업의 중요도에 따라 스레드의 우선순위를 서로 다르게 지정하여 특정 스레드가 더 많은 작업시간을 갖도록 할 수 있다.
예를 들어 파일 전송기능이 있는 메신저의 경우, 파일 다운로드를 처리하는 스레드보다 채팅 내용을 전송하는 스레드의 우선순위가 더 높아야 사용자가 채팅하는데 불편함이 없을 것이다. 대신 파일전송이나 다운로드에 걸리는 시간은 더 길어질 것이다.
시각적인 부분이나 사용자에게 빠르게 반응해야하는 작업은 스레드의 우선순위가 다른 작업을 수행하는 스레드에 비해 높아야하며 스레드의 우선순위와 관련된 메서드와 상수는 다음과 같다.
void setPriority(int newPriority) 스레드의 우선순위를 지정한 값으로 변경한다.
int getPriority() 스레드의 우선순위를 반환한다.
public static final int Max_PRIORITY = 10 // 최대 우선순위
public static final int MIN_PRIORITY = 1 // 최소 우선순위
public static final int NORM_PRIORITY = 5 // 기본 우선순위스레드가 가질 수 있는 우선순위의 범위는 1~10이며 숫자가 높을수록 높은 우선순위를 가지며 스레드의 우선순위는 스레드를 생선한 스레드로부터 상속받는다. main메서드를 수행하는 스레드의 경우 우선순위가 5이므로 main메서드 내에서 생성한느 스레드의 우선순위는 자동적으로 5가 된다.
package javastudy; public class MultiProcessing { public static void main(String[] args) { MyThread1 t1 = new MyThread1(); Runnable r = new MyThread2(); Thread t2 = new Thread(r); t2.setPriority(7); t1.start(); t2.start(); } } class MyThread1 extends Thread { public void run() { for (int i = 0; i < 500; i++) { System.out.print(0); } } } class MyThread2 implements Runnable { public void run() { for (int i = 0; i < 500; i++) { System.out.print(1); } } }
그러나 절대적으로 그 우선순위를 따르지 않는다는 것을 위의 예제를 통해 확인가능하다. OS마다 다른 방식으로 스케쥴링하고, 어떤 OS에서 실행하느냐에 따라 다른 결과를 얻을 수 있기 때문에 어느 정도 예측만 가능한 정도일 뿐 정확하게 알 수는 없다.
Main 쓰레드
main메서드에서 작업을 수행하는것도 스레드이며, 이를 main 스레드라고 한다. 위의 예시에서 하나의 메뉴(프로그램)을 만드는 데 요리사가 최소 하나의 작업은 실행해야 한다. 프로그램을 실행하면 기본적으로 하나의 스레드를 생성하고, 그 스레드가 main메서드를 호출해 작업이 수행되도록 하는 것이다.
main메서드가 수행을 마치면 프로그램이 종료된다. 그러나 main메서드가 수행을 마쳤다고해도 다른 스레드가 아직 작업을 마치지 않은 상태라면 프로그램은 종료되지 않는다. 스레드는 사용자 스레드와 데몬 스레드 두 종류가 있고
'프로그램은 실행 중인 사용자 스레드가 하나도 없을 때 종료된다.'
사용자 스레드
데몬 스레드를 제외한 모든 스레드이다.
데몬 스레드
데몬 스레드는 다른 일반 스레드의 작업을 돕는 보조적인 역할을 수행하는 스레드이다. 일반 스레드가 종료되면 데몬 스레드는 강제적으로 자동종료되며, 데몬 스레드의 예로는 가비지 컬렉터, 워드프로세서의 자동저장, 화면자동갱신 등이 있다.
스레드를 생성한 다음 실행하기 전 setDaemon(true)를 호출하기만 하면 된다. 데몬 스레드가 생성한 스레드는 자동적으로 데몬스레드가 된다는 점도 기억해두자.
데몬 스레드의 작성방법
boolean isDaemon() 스레드가 데몬 스레드인지 확인한다. 데몬 스레드일 경우 true 반환.
void setDeamon(boolean on) 스레드를 데몬스레드 또는 사용자 스레드로 변경한다.
매개 변수on의 값이 true인 경우 데몬스레드가 된다.동기화
멀티스레드 프로세스의 경우 여러 스레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로의 작업에 영향을 주게 된다. 만약 스레드1이 작업하던 도중 다른 스레드2에게 제어권이 넘어갔을 때, 스레드1이 작업하던 공유데이터를 스레드2가 임의로 변경한다면, 다시 스레드1이 제어권을 받아 나머지 작업을 마쳤을 때 의도했던 것과 다른 결과를 얻을 수 있다. 이런 일이 발생하는 것을 방지하기 위해 한 스레드가 특정 작업을 끝내기 전까지 다른 스레드에 의해 방해받지 않도록 하는 것이 필요하고, 그래서 도입된 개념이 바로 '임계영역과 잠금'이다.
공유 데이터를 사용하는 코드 영역을 임계 영역으로 지정하고 공유 데이터가 가지고 있는 lock을 획득한 단 하나의 스레드만 이 영역 내의 코드를 수행할 수 있게 한다. 그리고 해당 스레드가 임계 영역 내의 모든 코드를 수행하고 벗어나 lock을 반납해야만 다른 스레드가 반납된 lock을 획득하여 임계 여역의 코드를 수행할 수 있게 된다.
이처럼 한 스레드가 진행 중인 작업을 다른 스레드가 간섭하지 못하도록 막는 것을 '스레드의 동기화'라고 한다.
스레드의 동기화 방법 중 가장 간단한 synchronized 키워드를 이용한 동기화에 대해 알아보자.
이 키워드는 임계 영역을 설정하는데 사용되며, 메서드 전체를 임계 영역으로 지정하거나, 특정 영역을 임계 영역으로 지정하는 두 가지 방식이 있다.
1. 메서드 전체를 임계 영역으로 지정
public synchropnized void calcSum() {
}
2. 특정한 영역을 임계 영역으로 지정
synchronized(객체의 참조변수) {
}첫 번째 방법의 경우 스레드는 synchronized 메서드가 호출된 시점부터 해당 메서드가 포함된 객체의 lock을 얻어 작업을 수행하다가 메서드가 종료되면 lock을 반환한다.
두 번째 방법은 메서드 내의 코드 일부를 블럭{}으로 감싸 블럭 앞에 synchronized(참조변수)'를 붙이는 것인데, 이때 참조변수는 락(lock)을 걸고자하는 객체를 참조해야한다. 이 블럭 영역 안으로 들어가면서 스레드는 지정된 객체의 lock을 얻게 되고, 이 블럭을 벗어나면 lock을 반납한다.
모든 객체는 lock을 하나씩 가지고 있으며, 해당 객체의 lock을 가지고 있는 스레드만 임계 영역의 코드를 수행할 수 있다. 그리고 다른 스레드들은 lock을 얻을 때 까지 기다리게 된다. 임계영역은 멀티스레드 프로그램의 성능을 좌우하기 때문에 메서드 전체에 락을 거는 것보단 {}블럭으로 임계 영역을 최소화해 보다 효율적인 프로그램이 되도록 해야 한다.
예제)
package javastudy; public class MultiProcessing { public static void main(String[] args) { Runnable r = new ThreadEx_1(); new Thread(r).start(); new Thread(r).start(); } } class Account { private int balance = 1000; //잔고 public int getBalance() { return balance; } public void withdraw(int money) { // 잔고가 출금액보다 클때만 출금을 실시하므로 잔고가 음수가 되는 일은 없어야함 if (balance >= money) { try { // 문제 상황을 만들기 위해 고의로 쓰레드를 일시정지 Thread.sleep(1000); } catch (InterruptedException e) {} balance -= money; } } } class ThreadEx_1 implements Runnable { Account account = new Account(); @Override public void run() { while (account.getBalance() > 0) { // 100, 200, 300 중 임의의 값을 선택해서 출금 int money = (int) (Math.random() * 3 + 1) * 100; account.withdraw(money); System.out.println("balance: " + account.getBalance()); } } }
분명 잔고는 음수가 되지 않도록 설계했는데 음수가 나왔다. 왜냐하면 쓰레드 하나가 if문을 통과하면서 balance를 검사하고 순서를 넘겼는데, 그 사이에 다른 쓰레드가 출금을 실시해서 실제 balance가 if문을 통과할 때 검사했던 balance보다 적어지게 된다. 하지만 이미 if문을 통과했기 때문에 출금은 이루어지게 되고 음수가 나오는 것이다. 이 문제를 해결하려면 출금하는 로직에 동기화를 해서, 한 쓰레드가 출금 로직을 실행하고 있으면 다른 쓰레드가 출금 블록에 들어오지 못하도록 막아줘야 한다.
package javastudy; public class MultiProcessing { public static void main(String[] args) { Runnable r = new ThreadEx_1(); new Thread(r).start(); new Thread(r).start(); } } class Account { private int balance = 1000; //private으로 해야 동기화 의미가 있다. public int getBalance() { return balance; } public synchronized void withdraw(int money) { // 메서드 동기화 if (balance >= money) { try {Thread.sleep(1000);} catch (InterruptedException e) {} balance -= money; } } } class ThreadEx_1 implements Runnable { Account account = new Account(); @Override public void run() { while (account.getBalance() > 0) { // 100, 200, 300 중 임의의 값을 선택해서 출금 int money = (int) (Math.random() * 3 + 1) * 100; account.withdraw(money); System.out.println("balance: " + account.getBalance()); } } }
메서드에 synchronized를 붙임으로써 음수값이 나타나지 않은 것을 확인할 수 있다. 한 가지 주의사항은 Account 클래스의 인스턴스 변수인 balance의 접근 제어자가 private이라는 것이다. 만일 private이 아니면, 외부에서 직접 접근할 수 있기 때문에 아무리 동기화를 해도 이 값의 변경을 막을 길이 없다. synchronized를 이용한 동기화는 지정된 영역의 코드를 한 번에 하나의 스레드가 수행하는 것을 보장하는 것일 뿐이기 때문이다.
동기화된 임곙 영역의 코드를 수행하다 작업을 더 이상 진행할 상황이 아니면, 일단 wait()을 호출해 스레드가 락을 반납하고 기다리게 한다. 그러면 다른 스레드가 락을 얻어 해당 객체에 대한 작업을 수행할 수 있게 된다. 나중에 작업을 진행할 수 있는 상황이 되면 norifty()를 호출해 작업을 중단했던 스레드가 다시 락을 얻어 작업을 진행할 수 있게 한다.
비유를 들자면 빵을 사려고 빵집 앞에 줄을 서 있는 것과 유사하다. 자신의 차례가 되었는데도 자신이 원하는 빵이 나오지 않는다면, 다음 사람에게 순서를 양보하고 기다리다가 자신이 원하는 빵이 나오면 통보를 받고 빵을 사는 것이다.
다만 오래 기다린 스레드가 락을 얻는다는 보장이 없다. wait()이 호출되면 실행 중이던 스레드는 해당 객체의 대기실(wating pool)에서 통지를 기다린다. 그 후 notify()가 호출되면, 해당 객체의 대기실에 있던 모든 스레드 중에 임의의 스레드만 통지를 받는다. notifyAll()은 기다리고 있는 모든 스레드에게 통보를 하지만, 그래도 lock을 얻을 수 있는 것은 하나의 스레드일 뿐이고 나머지 스레드는 통보를 받긴 하지만, lock을 얻지 못하면 다시 lock을 기다려야 한다.
wait()과 notify()는 특정 객체에 대한 것이므로 Object 클래스에 정의되어 있다. wait()은 norify() 또는 notifyAll()이 호출될 때까지 기다리지만, 매개변수가 있는 wait()은 지정된 시간동안만 기다린다. 지정된 시간이 지나면 자동으로 notify()가 호출된다.
그리고 waiting pool은 객체마다 존재하므로 모든 객체의 waintg pool에 있는 스레드가 깨워지는 게 아닌, notifyAll()이 호출된 객체의 waiting pool에 대기 중인 스레드만 해당된다.
wait(), notify(), notifyAll()
- Object에 정의되어 있다.
- 동기화 블록(synchronized 블록) 내에서만 사용할 수 있다.
- 보다 효율적인 동기화를 가능하게 한다.데드락
데드락은 한 자원을 여러 시스템이 사용하려고 할 때 발생할 수 있다.
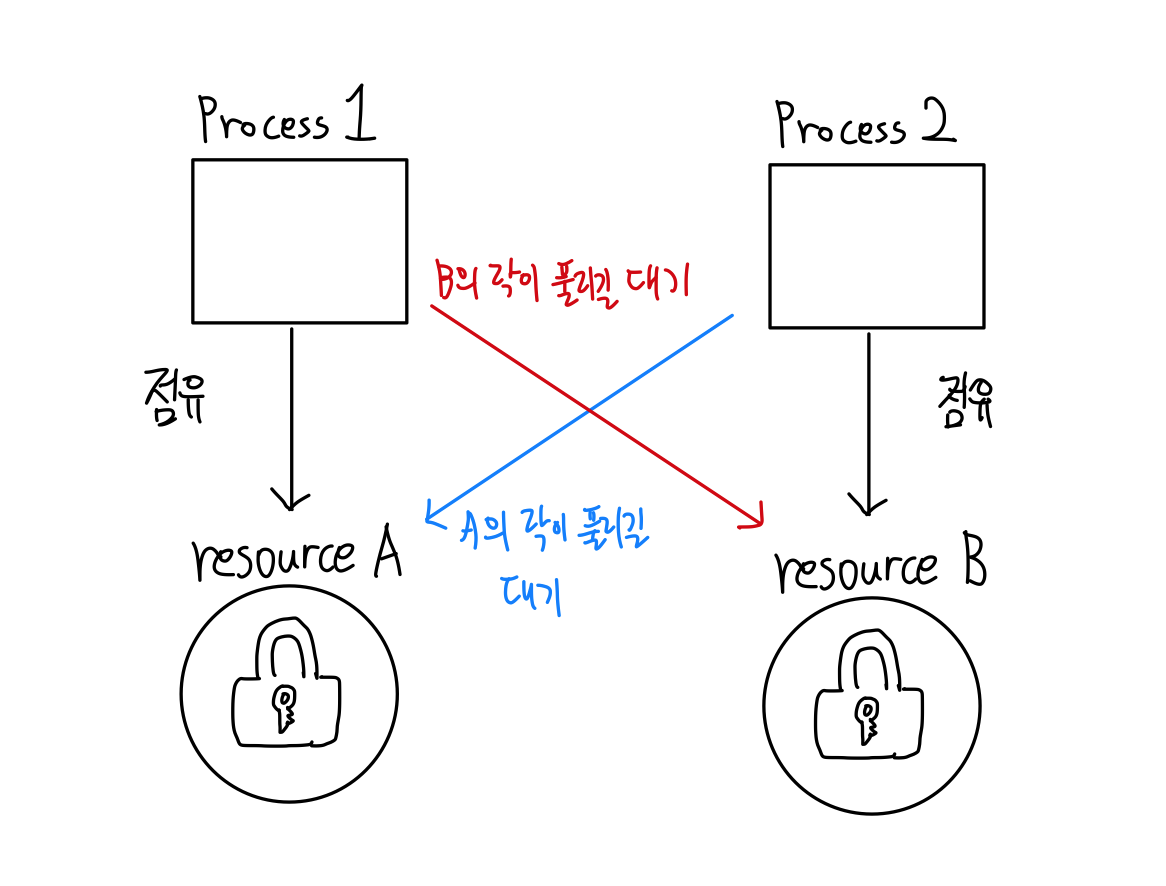
이미지 출처: https://wisdom-and-record.tistory.com/48 Process1과 Process2가 모두 자원 A, B가 필요한 상황이라고 가정하자. Process1은 A에 먼저 접근하고 Process2는 B에 먼저 접근했다. Process1과 Process2는 각각 A와 B의 lock을 가지고 있는 상태이다. 이제 Process1은 B에 접근하기 위해 B의 락이 풀리기를 대기한다. 동시에 Process2는 A에 접근하기 위해 A의 락이 풀리기를 대기한다. 서로 원하는 리소스가 상대방에게 할당되어 있기 때문에 두 프로세스는 무한히 대기 상태에 있게 되는데, 이를 데드락이라고 한다.
데드락은 한 시스템 내에서 다음의 네 가지 조건이 동시에 성립할 때 발생한다. 아래 네 가지 조건 중 하나라도 성립하지 않도록 만든다면 교착 상태를 해결할 수 있다.
1) 상호 배제 (Mutual exclusion)
- 자원은 한 번에 한 프로세스만이 사용할 수 있어야 한다.
2) 점유 대기 (Hold and wait)
- 최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 있어야 한다.
3) 비선점 (No preemption)
- 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 한다.
4) 순환 대기 (Circular wait)
- 프로세스의 집합 {P0, P1, ,…Pn}에서 P0는 P1이 점유한 자원을 대기하고 P1은 P2가 점유한 자원을 대기하고 P2…Pn-1은 Pn이 점유한 자원을 대기하며 Pn은 P0가 점유한 자원을 요구해야 한다.
(출처: https://jwprogramming.tistory.com/12 [개발자를 꿈꾸는 프로그래머])
참고.
자바의 정석, 남궁성
wisdom-and-record.tistory.com/48
https://jwprogramming.tistory.com/12
https://wisdom-and-record.tistory.com/48
'공부일기 > 자바 스터디' 카테고리의 다른 글
Java 항해일지 - 12. 애노테이션 (0) 2021.02.02 Java 항해일지 11. Enum (0) 2021.01.26 Java 항해일지 - 9. 예외 처리 (0) 2021.01.17 Java 항해일지 - 8. 인터페이스 (0) 2021.01.08 Java 항해일지 - 7. 패키지 (0) 2020.12.28